在Open WebUI中实现文生图
网上很多AI的平台都已经实现了在对话框里输入文字生成图片的功能,这回,我就利用本地的ComfyUI和Ollama里的大语言模型,借助Open WebUI,同样实现了这种文生图的功能,本文将分享一下部署的流程。对应的视频课程已先在视频号「退役程序员」中发布,欢迎大家关注。
第一步:ComfyUI 设置
- 打开ComfyUI,进入”Settings”面板。
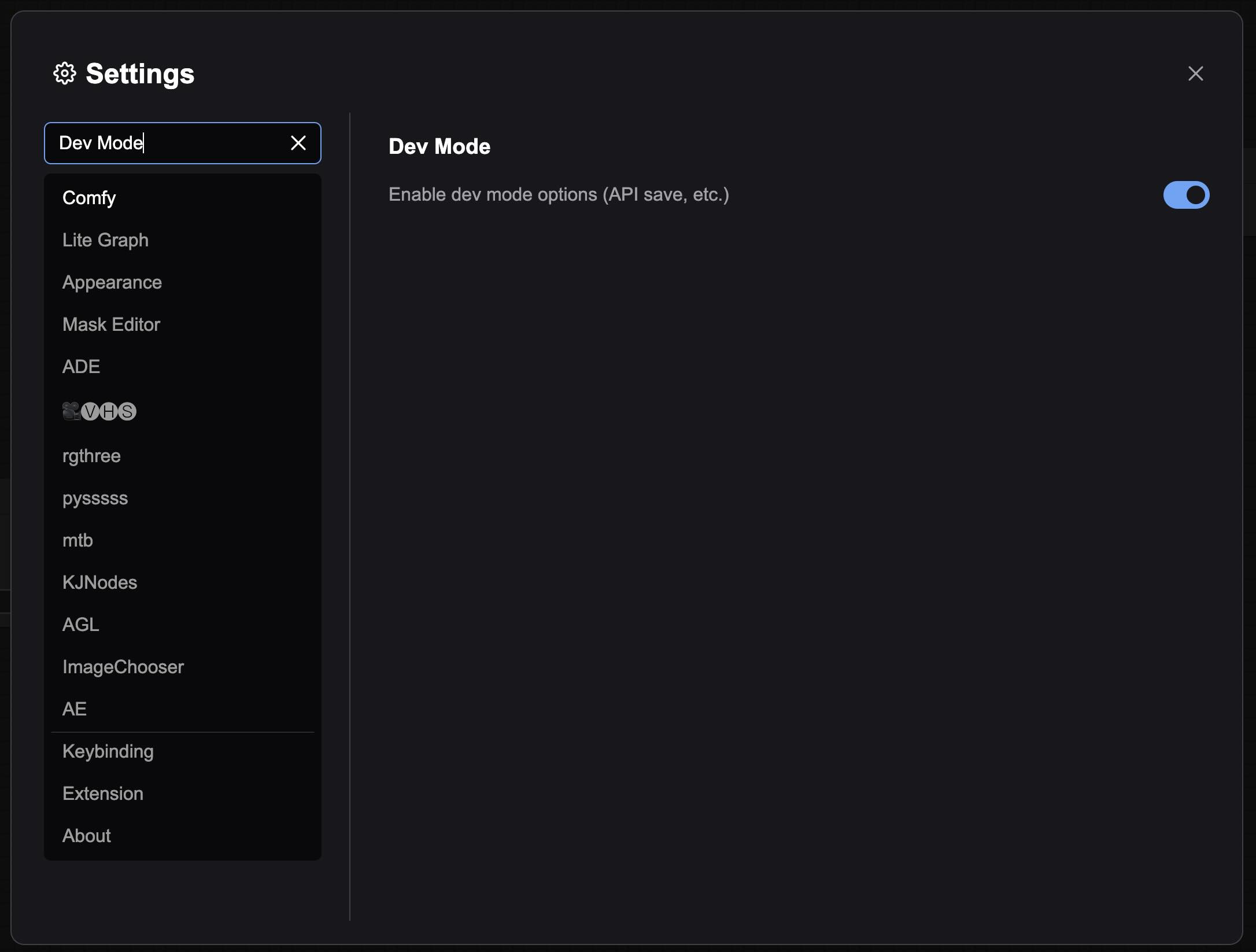
- 搜索”Dev Mode”,开启开发者模式。
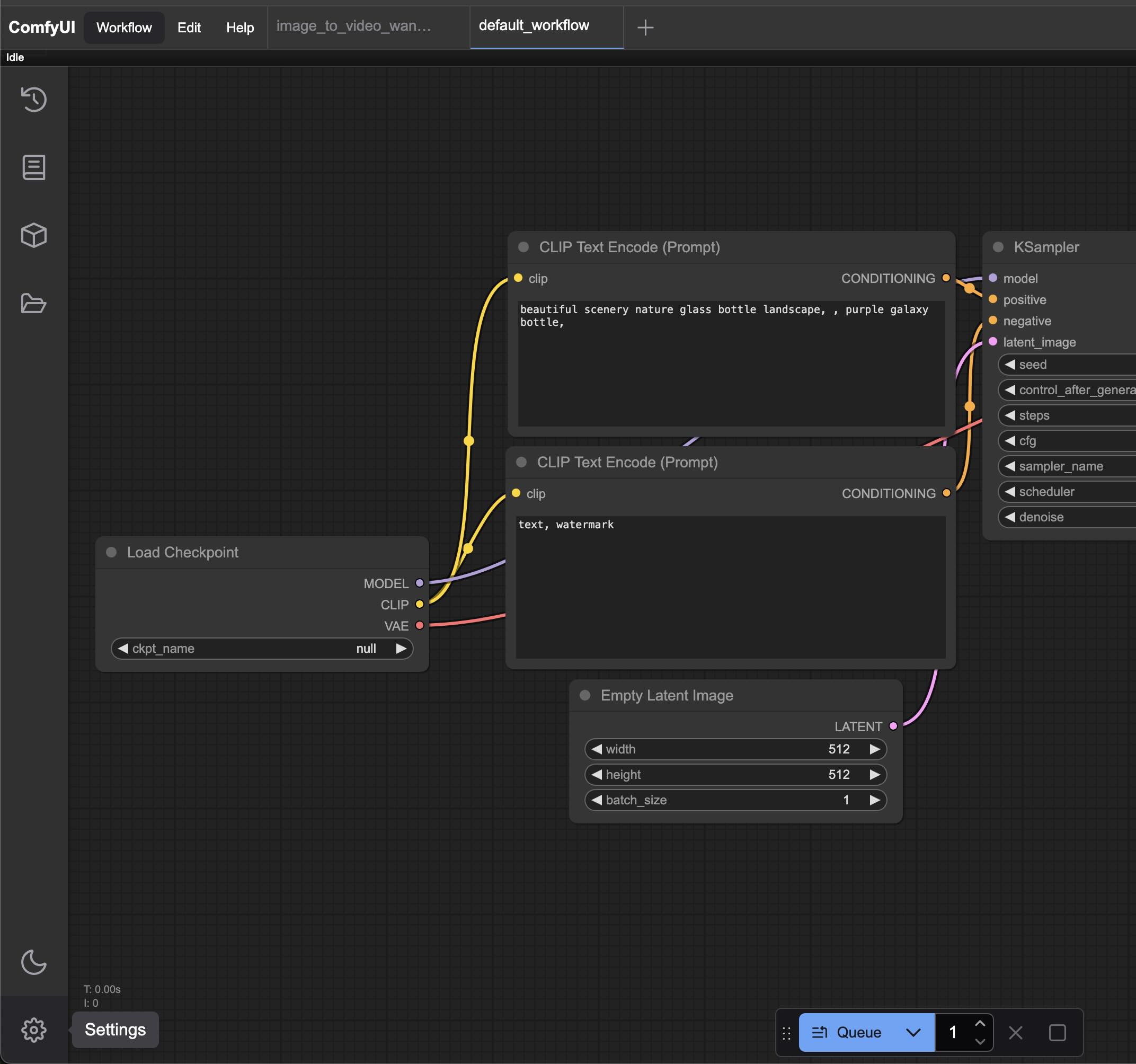
- 在Workflow菜单下,点击”Export(API)“,将工作流以API模式导出并保存至本地。

第二步:Open WebUI 设置
- 进入Open WebUI,在Settings中选择”Admin Settings”。
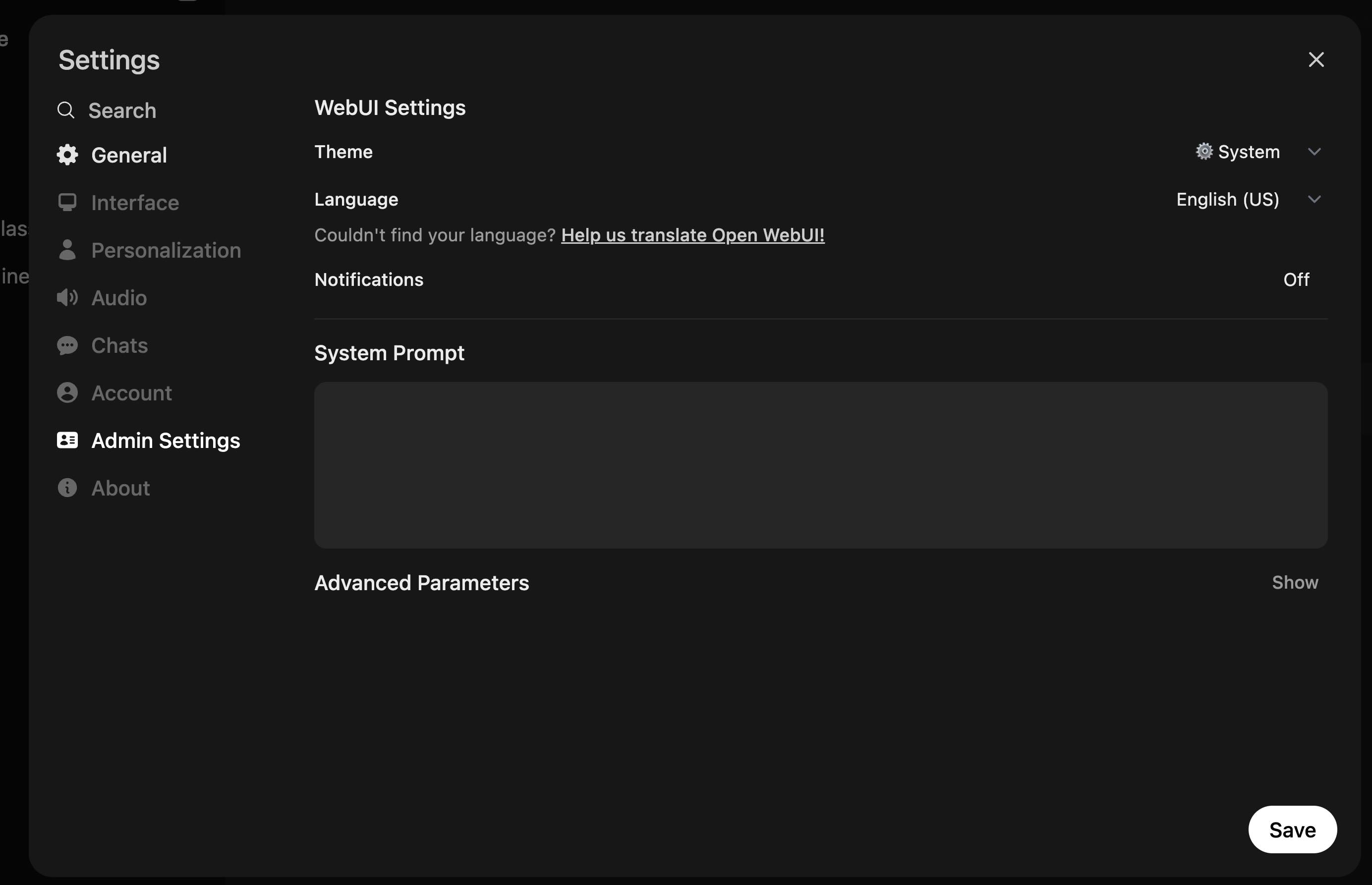
在窗口中选择”Images”,开启”Image Generation”选项。

设置ComfyUI的URL,这里需要注意,ComfyUI默认的URL是http://127.0.0.1:8188/,但是如果Open WebUI是在Docker上部署的,这里需要按照docker的路径填写。
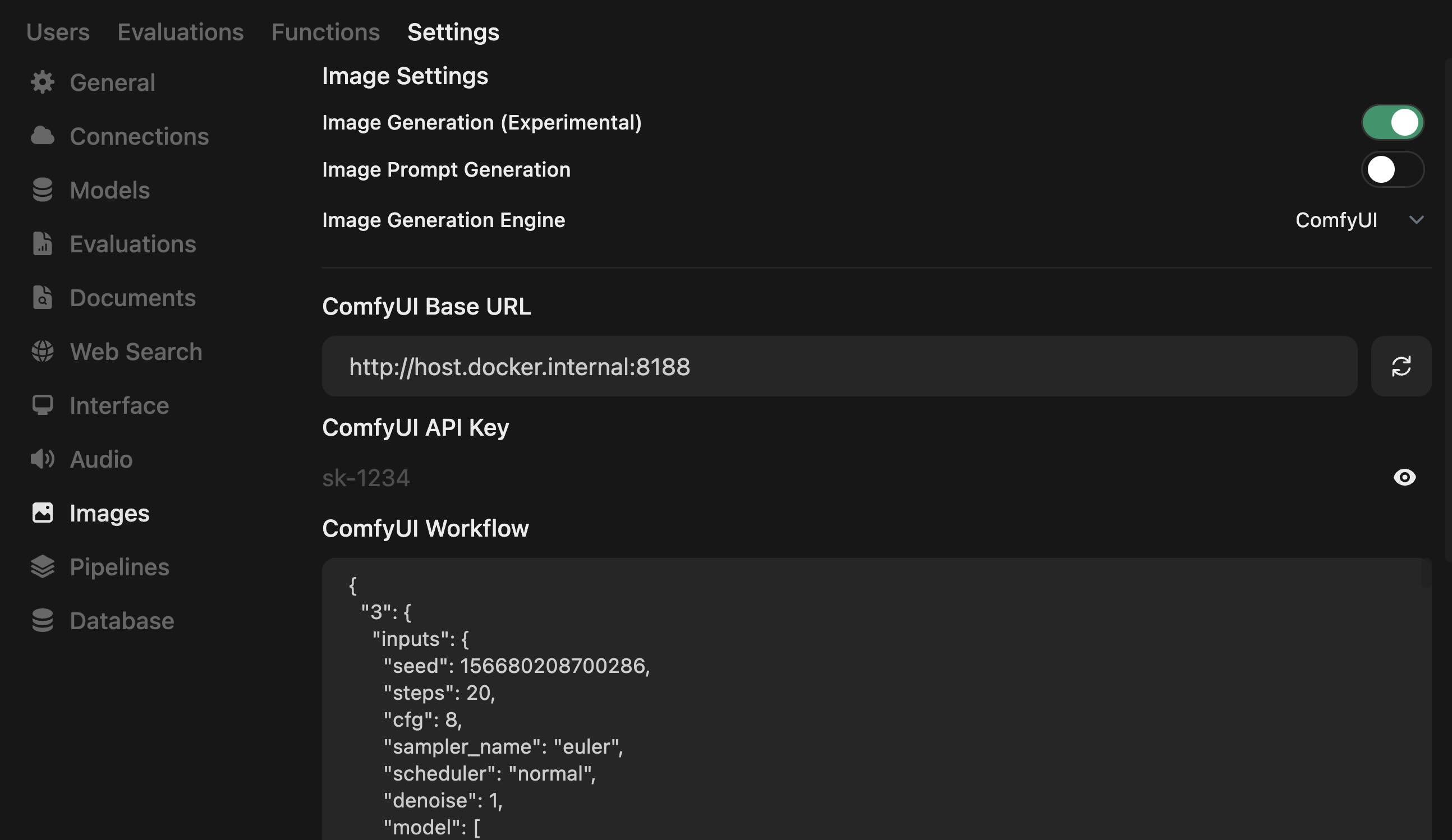
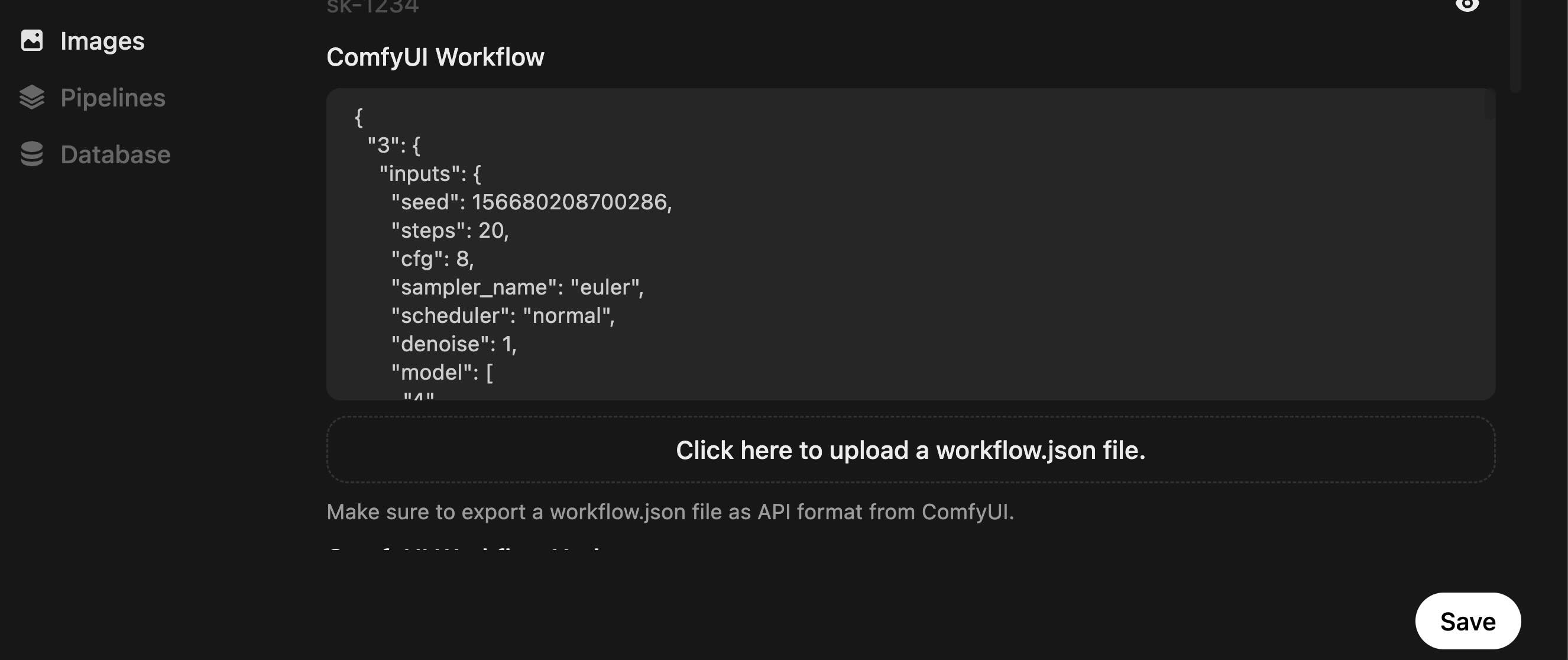
- 上传在ComfyUI中保存的API模式工作流,并根据其进行设置。
(1)点击”Click here to upload a workflow.json file”,选择ComfyUI中
以API模式导出的json工作流。
(2) 对应着”ComfyUI Workflow”中Json文件的内容修改”ComfyUI Workflow Nodes”列表中代表节点的数字。
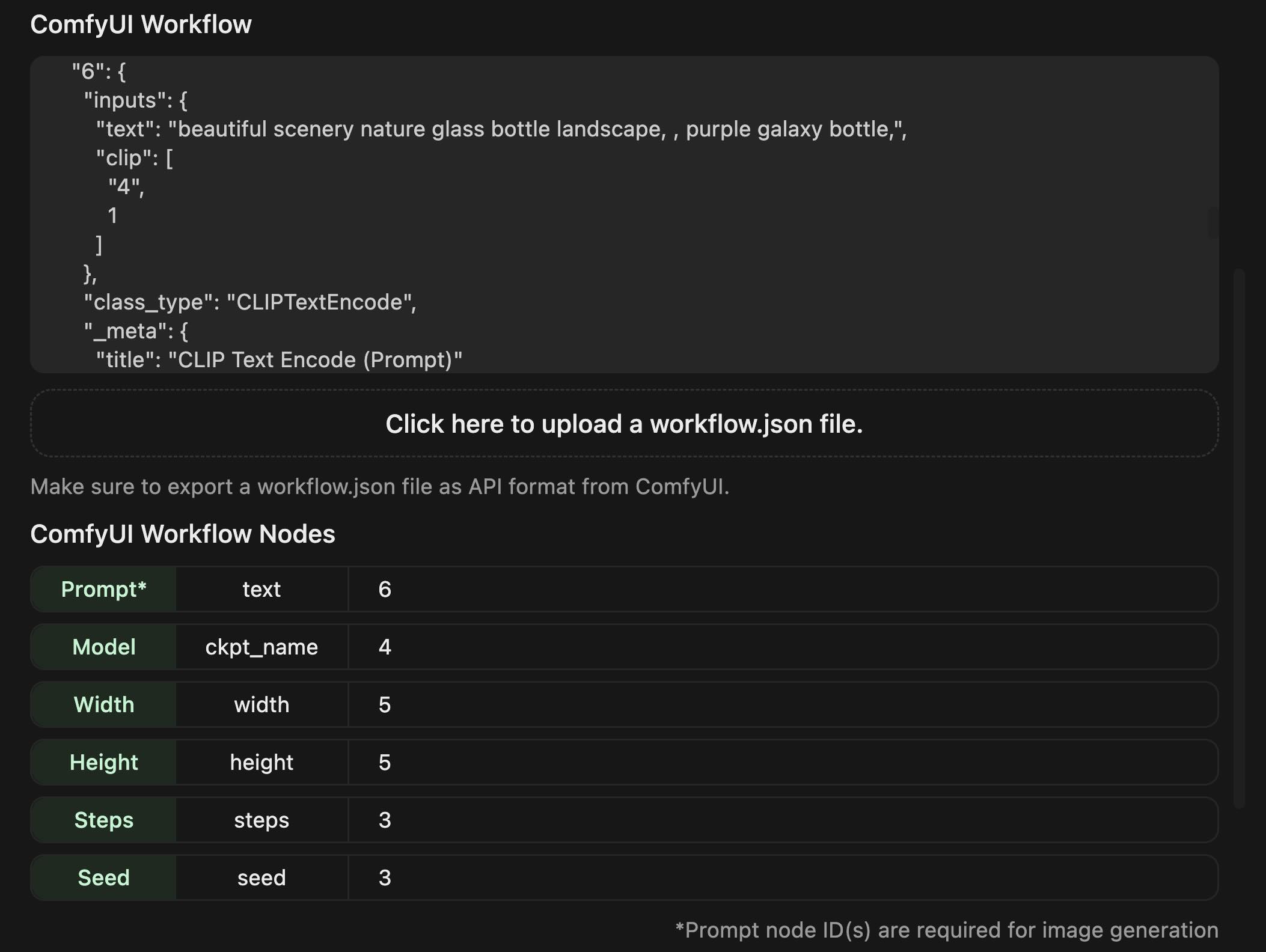
例如:prompt对应的text在节点6,在列表中就填写6。
在”Set Default Model”中选择ComfyUI中已经下载过的模型,设置图像大小和生成图像需要的steps,数值越大,通常会产生更清晰、更细致的图像,但消耗时间会随之变长(20到50步之间较为合理,不能过大)。
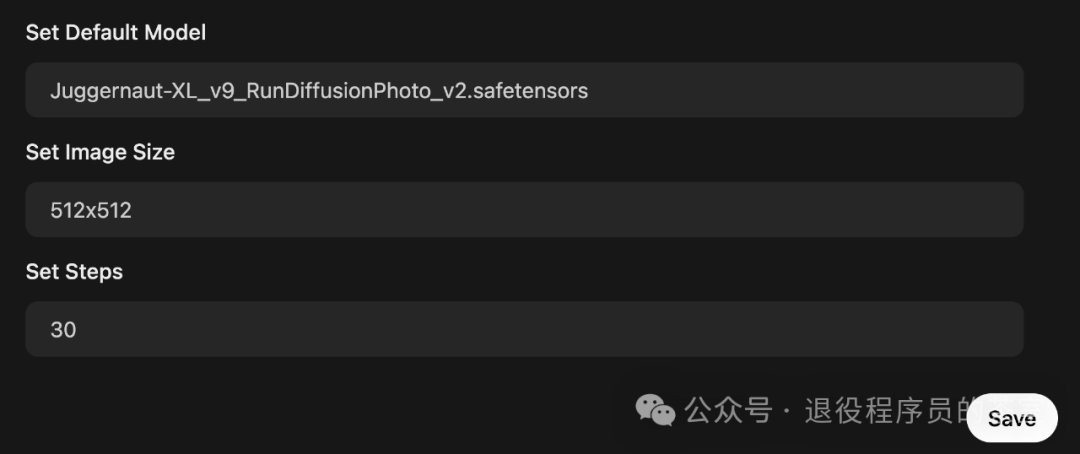
点击”Save”保存。
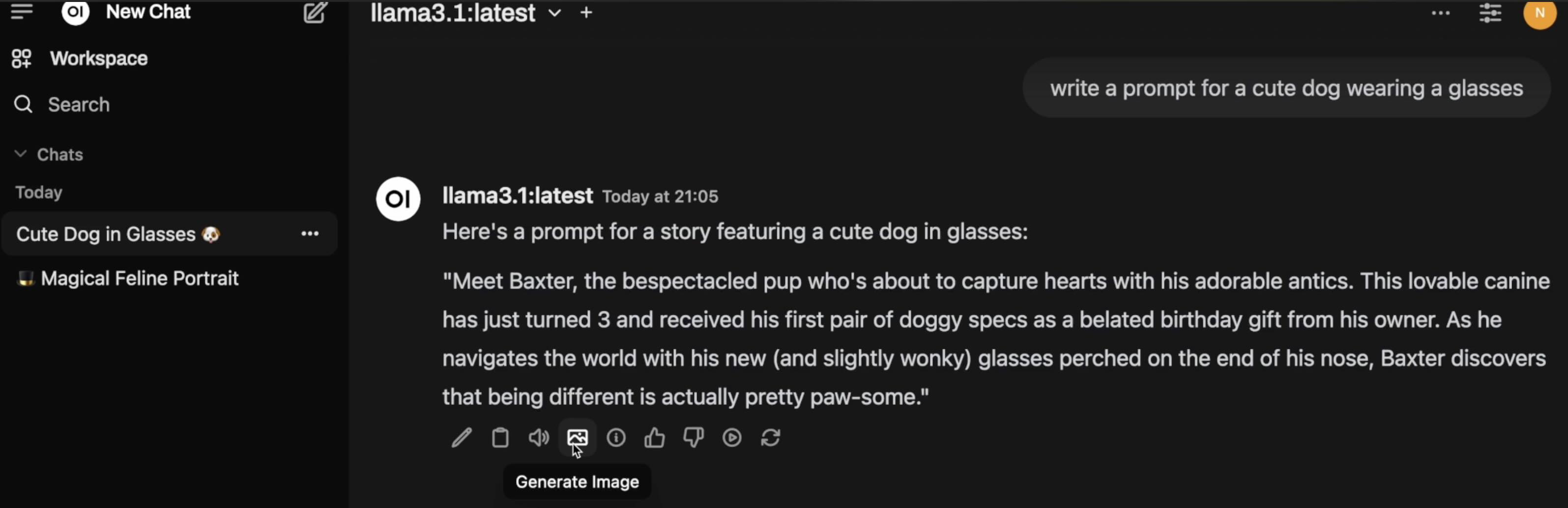
第三步:生成图像
在Open WebUI对话框中,开启新的对话。
选择本地大模型(例如:Llama 3.1)。
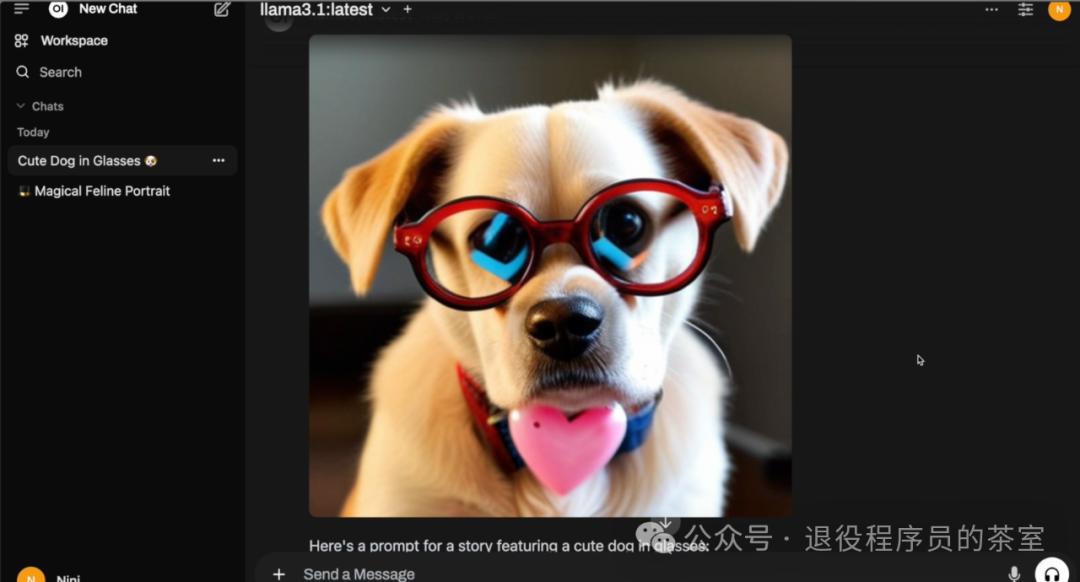
输入指令,例如“写一个生成带眼镜的可爱小狗图像的prompt”。这一步是借助LLM生成更为详细的提示词
生成提示词后,点击下方工具栏的图片图标(Generate Image)。
- 等待片刻,即可生成图像。